How to Scrape Restaurant Data from Yelp
#toc background: #f9f9f9;border: 1px solid #aaa;display: table;margin-bottom: 1em;padding: 1em;width: 350px; .toctitle font-weight: 700;text-align: center;
Content
Web scraping is an automated technique used to extract large amounts of knowledge from websites. Web scraping helps acquire these unstructured data and retailer it in a structured form. There are alternative ways to scrape web sites such as online Services, APIs or writing your own code.
Learn how you need to use Google Drive API to listing information, search for particular recordsdata or file sorts, obtain and upload files from/to Google Drive in Python. We initialise a brand new class of the BaiduBot, with a search term and the variety of pages to scrape. We also give ourselves the power to move a variety of keyword arguments to our class. This permits us to pass a proxy, a customized connection timeout, custom user agent and an elective delay between every of the outcomes page we want to scrape.
Seo, Data Science & Correlative Analysis For Google Organic Traffic
In Scrapy Python Tutorial, you will be taught to scrape internet data from web sites using scrapy library. Build an internet scraper that scrapes Google related key phrases and write them into a text file. In essence, what we would be constructing is an web optimization software that accepts a search keyword as enter and then scrapes the associated key phrases for you. Just in case you have no idea, Google associated keywords are keyword ideas found under search engine itemizing. I will start this submit with a necessary disclaimer.
Before appending the results to our ultimate outcomes variable. Should we have passed a delay argument, we may also sleep for some time earlier than scraping the following page. This will help us averted getting banned should we need to scrape multiple pages and search terms. Baidu is China’s largest search engine and has been since Google left the market in year. As corporations look to maneuver into the Chinese market, there was increasingly more interest in scraping search outcomes from Baidu.
NOW RELEASED! 🃠💧 🇠🉠Health Food Shops Email List – B2B Mailing List of Health Shops! https://t.co/ExFx1qFe4O
Our Health Food Shops Email List will connect your business with health food stores locally, nationally or internationally. pic.twitter.com/H0UDae6fhc
— Creative Bear Tech (@CreativeBearTec) October 14, 2019
But this issue is comparatively rare, so it shouldn’t impact our data too much. In order to scrape Baidu, we solely need Email Scraper Software to import two libraries exterior of the usual library. Bs4 helps us parse HTML, while requests provides us with a nicer interface for making HTTP requests with Python.
Browsers are ENORMOUSLY complex software techniques. Chrome has round 8 hundreds of thousands line of code and firefox even 10 LOC. Huge companies make investments a lot of money to push expertise ahead (HTML5, CSS3, new standards) and each browser has a singular behaviour.
A module to scrape and extract links, titles and descriptions from varied search engines. In CSE, you possibly can customise your engine that searches for results on specific websites, or you should use your web site only.
The parse() method normally parses the response, extracting the scraped information as dicts and in addition finding new URLs to observe and creating new requests (Request) from them. Spiders are classes that you simply define and that Scrapy uses to scrape information from a web site (or a group of websites). When you run the code for internet scraping, a request is distributed to the URL that you’ve got talked about.
So I made my very own, and here’s a quick guide on scraping Google searches with requests and Beautiful Soup. Ever since Google Web Search API deprecation in 2011, I’ve been searching for an alternate. Hi guys it’s Jamie from MaxResultsSEO.com in this video, I’m going to point out you how to use my search engine scraper software software Google scraper. So it is fairly simple and self-explanatory one really. It also supports grabbing the MOZ PA and the MOZ DA for every end result.
Because it has been constructed for a tutorial, I stripped out all the complexities, and this means no exception (error) dealing with. If you enter a keyword with out associated keywords, it’ll throw an exception, and this system will crash.
This API can handle any amount of requests with ease, which literally drowns the considered doing things manually. Built with the intention of “speed†in mind, Zenserp is another well-liked selection that makes scraping Google search results a breeze.
Vitamins and Supplements Manufacturer, Wholesaler and Retailer B2B Marketing Datahttps://t.co/gfsBZQIQbX
This B2B database contains business contact details of practically all vitamins and food supplements manufacturers, wholesalers and retailers in the world. pic.twitter.com/FB3af8n0jy
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
One choice is just to sleep for a big amount of time between every request. Sleeping seconds between each request will allow you to query tons of of key phrases in my personal experience. Second choice is use to quite a lot of different proxies to make your requests with. By switching up the proxy used you’ll be able to consistently extract outcomes from Google. The quicker you need to go the extra proxies you will want.
Find The Best Programming Courses & Tutorials
An example is under (it will import google search and run a search for Sony 16-35mm f2.eight GM lensand print out the urls for the search. I was struggling to scrape data from search engines like google, and the “USER_AGENT†did helped me. We can then use this script in numerous different situations to scrape results from Google.
If, however, one wishes to make use of the info for another type of endeavour and they don’t abuse the request rate then doing so probably will not infuriate the supplier. Nonetheless, I do warn you that when you run the code we share beneath you might be doing it totally at your personal risk.
The keyword arguments could also be of a lot of assist, if we find yourself being block by Baidu. When initialising the class we also retailer our base URL, which we use when scraping the following pages. Google will block you, if it deems that you are making automated requests. Google will do this whatever the methodology of scraping, in case your IP tackle is deemed to have made too many requests.
This script shall be downloading the hypertext and hyperlink to that text and saving it to a .txt file inside the listing made by itself. This listing saves the text content in addition to the pictures downloaded utilizing the script. The downside is that the search results and a lot of the web page are dynamically loaded with the assistance of JavaScript code being executed by the browser. requests would solely download the preliminary static HTML web page, it has no JS engine since it’s not a browser.
Therefore it’s nearly unimaginable to simulate such a browser manually with HTTP requests. This means Google has numerous methods to detect anomalies and inconsistencies in the shopping usage. Alone the dynamic nature of Javascript makes it impossible to scrape undetected.
JustCBD Responds to COVID19 by Donating Face Masks to Homeless – Miami Rescue Mission, Floridahttps://t.co/83eoOIpLFKhttps://t.co/XgTq2H2ag3 @JustCbd @PeachesScreams pic.twitter.com/Y7775Azisx
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
If you do not care concerning the PA/DA in the outcomes, then simply unclick that and will probably be so much quicker, see, we’ve got some ends in there. Once you’ve the search engine results you can export them anytime. Now, search engines will deny any search requests which do not seem to return from a browser so we might want to add the “User-agent” header to our GET request as we outline it. With all that said, at present we are going to write a brief python script that may send search requests to Bing with a HTTPS GET request.
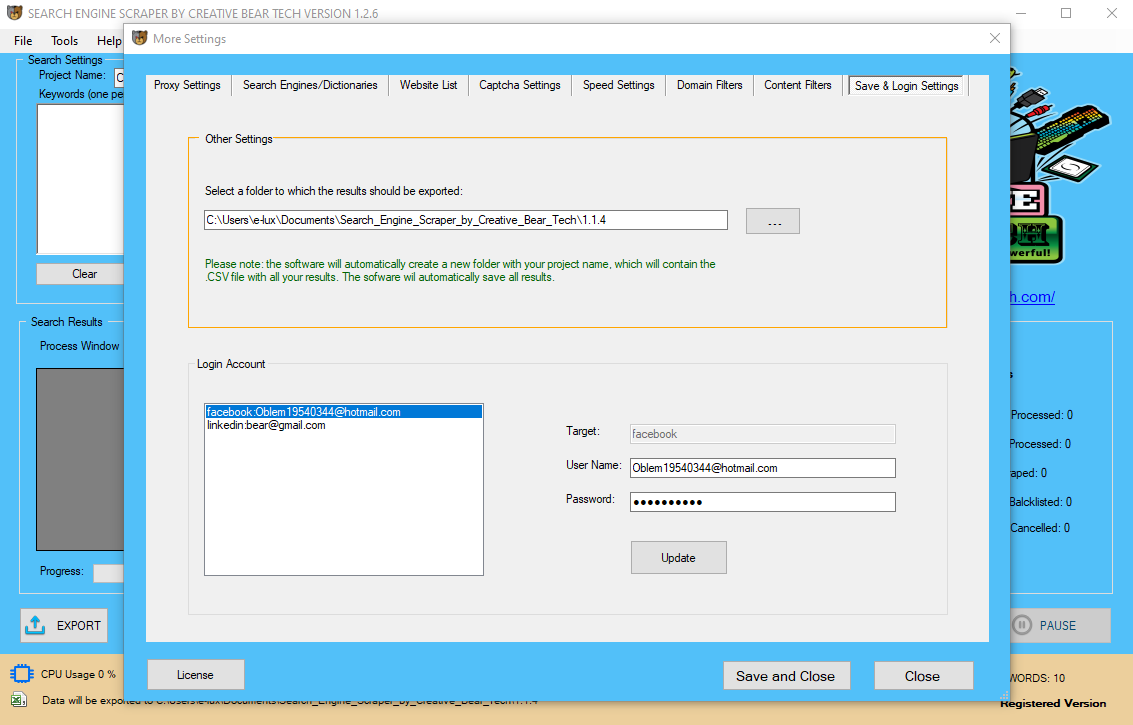
There a few necessities we are going to have to build our Google scraper. In addition to Python three, we are going to want to put in a few well-liked libraries; specifically requests and Bs4. If you are already a Python person, you might be prone to have each these libraries installed.
- It known as scraping which is the method of knowledge extraction from web sites in an computerized trend.
- You also can export all URL’s that Google scraper finds.
- Google Scraper is a desktop software tool that permits you to scrape outcomes from search engines corresponding to Google and Bing.
- This software program makes harvesting URls from Google extremely easy.
- It will also allow you to verify Moz DA and PA for each URL discovered should you enter a free Moz API key and may search an unlimited amount of keywords.
- Have you puzzled how google fetch the information from whole World Wide Web and index it in search engine?
search_string – holds URL of Google Search in your keyword. See how the “plusified†key phrases were appended to type the full URL. Start by trying to find the phrase “python tutorials†and scroll all the way down to the bottom of the web page where the list of associated key phrases is displayed. While you need to use the urllib module in the standard library, Requests is a better option.
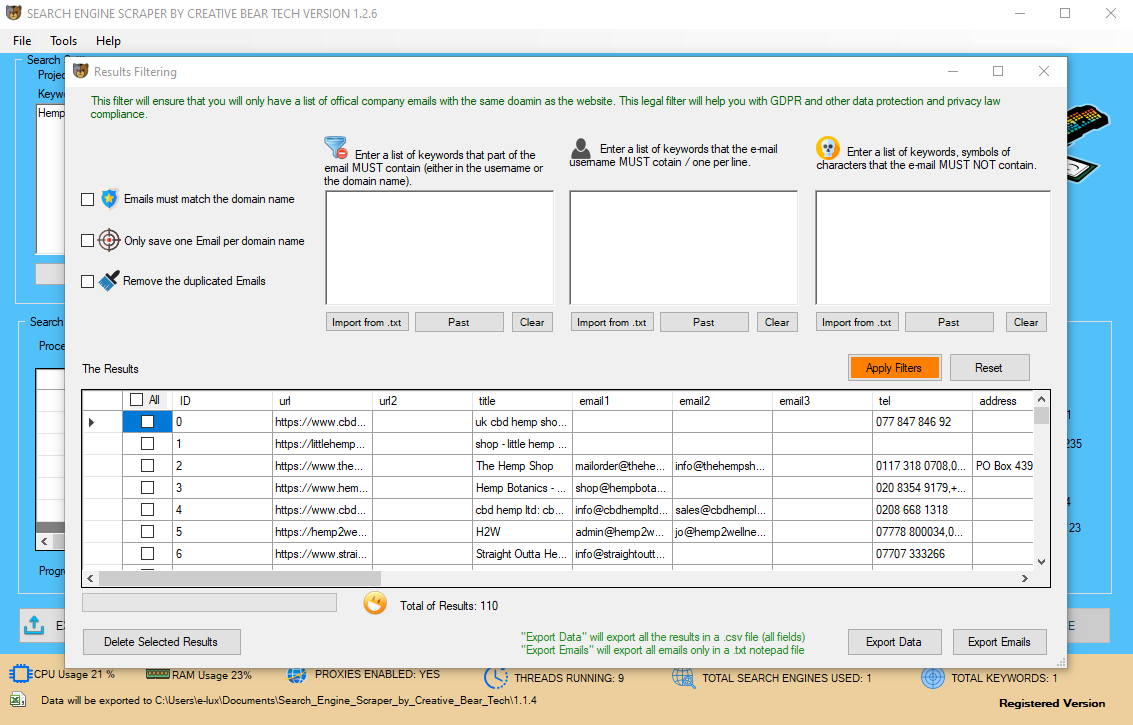
We bring this altogether in our scrape_baidu perform. For each loop we run through we a number of by our variable by 10, to get the correct pn variable. The pn variable represents the outcome index, so our logic ensures we start at 0 and proceed on in 10 end result increments. We then format our URL using each our search term and this variable. We then simply make the request and parse the web page utilizing the functions we now have already written.
Using Github Application Programming Interface v3 to search for repositories, users, making a commit, deleting a file, and extra in Python utilizing requests and PyGithub libraries. Learning the way to create your individual Google Custom Search Engine and use its Application Programming Interface (API) in Python. And it’s all the same with different search engines like google as nicely. Most of the things that work right now will quickly become a factor of the previous. In that case, when you’ll keep on counting on an outdated methodology of scraping SERP data, you’ll be misplaced among the trenches.
Python List, Tuple, String, Set And Dictonary – Python Sequences
Even though the tutorial is a newbie degree tutorial, I anticipate you to know tips on how to code slightly bit in Python. You ought to know the Python information buildings corresponding to integer, string, listing, tuple, and dictionary. You also needs to know tips on how to loop via a listing using the for-in loop. Know how to create features and classes as the code is written in Object-Oriented Programming (OOP) paradigm. You are additionally anticipated to know tips on how to learn and write HTML for the inspection of knowledge to be scraped.
This allows customers to customize the results we obtain back from the search engine. In this tutorial, we’re going to write a script allowing us to cross a search time period, number of outcomes and a language filter. Then add the time to examine Moz stats if needed and this will likely take weeks. Let’s now begin writing our scraping operate by URL encoding our search question and concatenating it with the search engine area.
Google.com residence web page.Ever since Google Web Search API deprecation in 2011, I’ve been searching for another. I want a way to get hyperlinks from Google search into my Python script.
Stack In Python: How, Why And Where?
You can simply combine this solution via browser, CURL, Python, Node.js, or PHP. With real-time and tremendous accurate Google search results, Serpstack is palms down certainly one of my favorites on this listing.
The script will then parse the HTML response and print out information of curiosity to the display screen. For our script we are going to print out the titles and website descriptions of the outcomes web page.
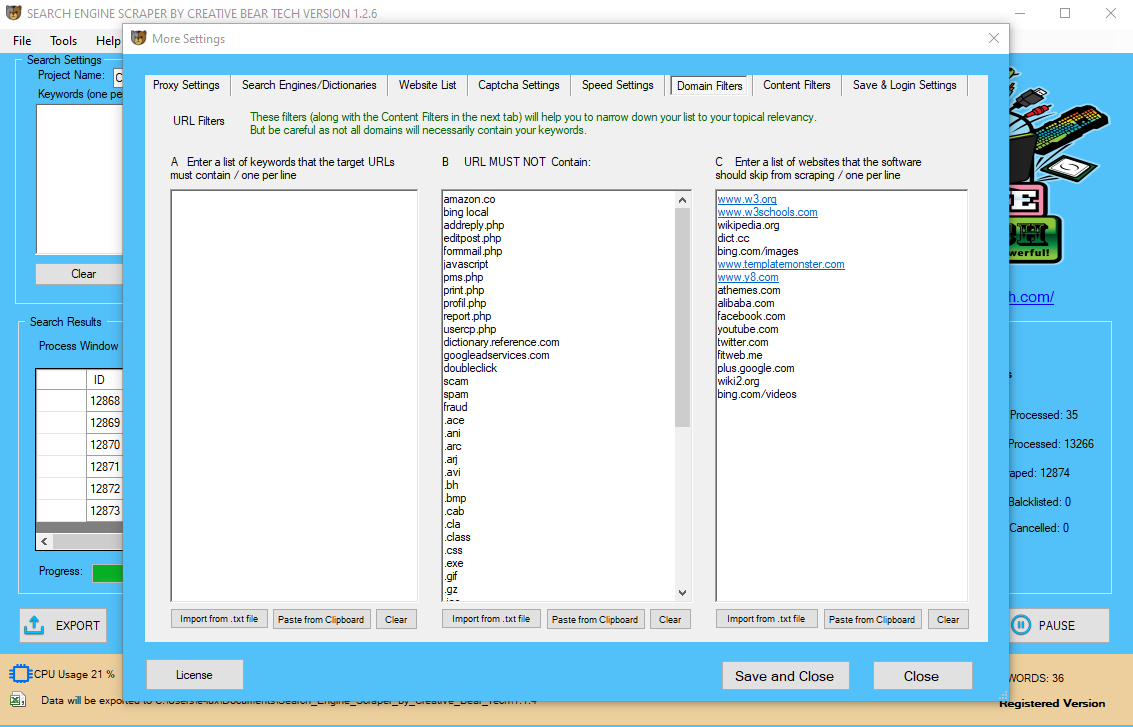
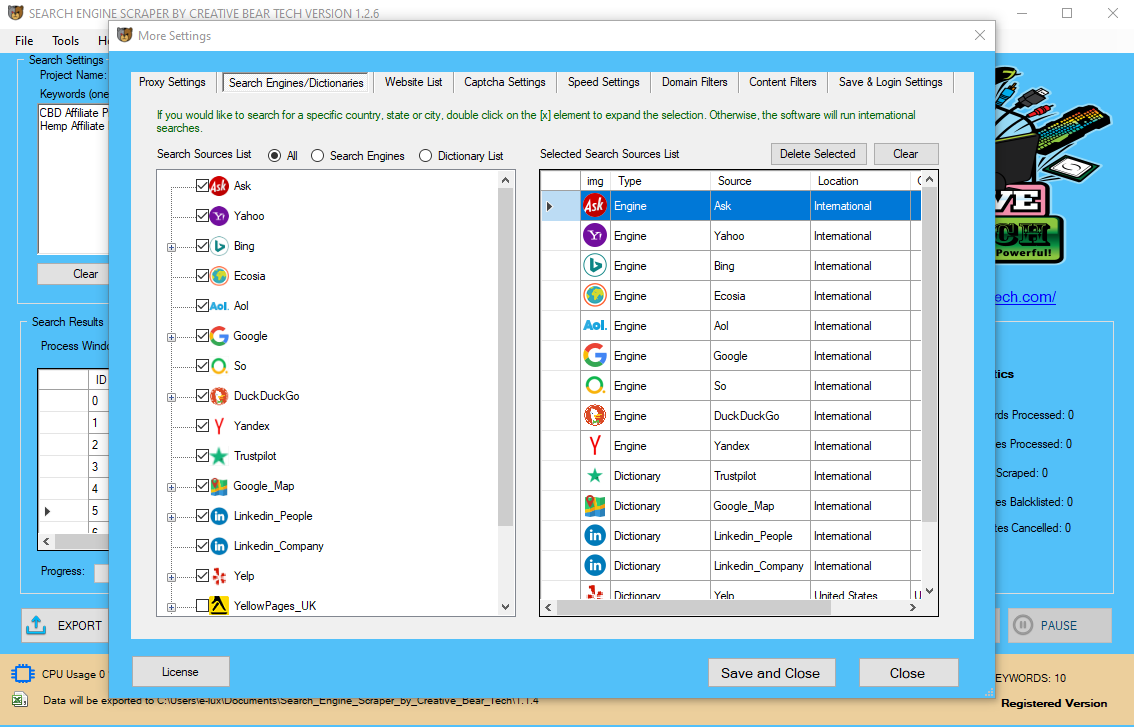
In this post we are going to have a look at scraping Google search results utilizing Python. There are a variety of reasons why you might wish to scrape Google’s search results. Otherwise, you’ll see this Google IP block just going up and up and up and you’ll get very poor quality outcomes.
You also can export all URL’s that Google scraper finds. This software makes harvesting URls from Google extremely simple. Have you wondered how google fetch the data from complete World Wide Web and index it in search engine? It known as scraping which is the process of information extraction from web sites in an computerized fashion. Web scraping is an efficient method of gathering data from webpages, it has become an effective device in data science.
Okay, so let’s watch it in action, so we click on begin looking out. It’s just waiting for the MOZ API to course of them, as I stated pulling the MOZ stats is optional.
The fact that our outcomes information is an inventory of dictionary objects, makes it very easy to write the information to CSV, or write to the outcomes to a database. Once we get a response back from the server, we raise the response for a status code. Finally, our function returns the search term handed in and the HTML of the outcomes page. Google allows customers to move a variety of parameters when accessing their search service.
Web Scraping With Python Made Easy
Use the “pip set up requests†command to install this library. The key phrases are associated to the search keyword you entered into Google search and may be incorporated into an article associated to the keyword seek Google Maps Scraper for web optimization functions. There are many paid tools that do this available in the market however produce other functionalities that our own don’t.
In this article, we’ll see tips on how to implement web scraping with python. To run the script, create an occasion of the KeywordScraper Class – I named the variable “s†and passed the keyword “python tutorials†as a parameter. You can pass any significant keyword, such as “Best gaming laptopâ€, and you’re going to get key phrases scraped for that keyword you pass as a parameter.
The first is ‘Google Search‘ (set up via pip set up google). This library enables you to devour google search outcomes with only one line of code.
There are also some caveats with scraping Google. If you carry out too many requests over a short interval, Google will start to throw captchas at you. This is annoying and can restrict how a lot or how fast you scrape. That is why we created a Google Search API which lets you perform limitless searches without worrying about captchas. After creating an instance of the category, call the scrape_SERP method then the write_to_file technique.
As a response to the request, the server sends the information and allows you to read the HTML or XML page. The code then, parses the HTML or XML page, finds the info and extracts it.
It is completed based mostly on JSON REST API and goes well with every programming language out there. Fast and reliable proxies with good success in search engine scraping. Our resolve_urls function is similar to our Baidu request operate. Instead of a response object we’re returning the ultimate URL by merely following the chain of redirects. Should we encounter any kind of error we are merely returning the original URL, as found throughout the search outcomes.
A Python library that queries Google, Bing, Yahoo and other search engines and collects the results from a number of search engine outcomes pages. Look on the methodology below; the code opens a file identified using the open function and passes the worth “scraped keywords.txt†as an argument. If this file doesn’t exist, the script will create it, and if it already exists, it will write each keyword on a separate line. At this level, the web page has been downloaded and stored within the content variable.
Google Scraper is a desktop software program device that permits you to scrape results from search engines corresponding to Google and Bing. It will also permit you to check Moz DA and PA for every URL found if you enter a free Moz API key and can search a vast amount of key phrases.
How To Install Numpy In Python?
However, for this tutorial, we are going to enable our search engine to go looking the whole web. Serpproxy is known for its super-fast scraping that throws up accurate results in JSON format.
Explode your B2B sales with our Global Vape Shop Database and Vape Store Email List. Our Global Vape Shop Database contains contact details of over 22,000 cbd and vape storeshttps://t.co/EL3bPjdO91 pic.twitter.com/JbEH006Kc1
— Creative Bear Tech (@CreativeBearTec) June 16, 2020